
Ventajas, desafíos y casos donde realmente aporta valor
En los últimos años, las organizaciones han pasado de trabajar con bases de datos centralizadas a ecosistemas distribuidos, complejos y en continuo crecimiento. Este cambio ha generado la necesidad de repensar la forma en que los datos se gestionan, se comparten y se transforman en valor. Frente a este escenario, surge Data Mesh, un paradigma que promueve la descentralización y el trabajo colaborativo entre equipos, rompiendo el modelo tradicional de plataformas centralizadas.
Data Mesh no es simplemente una arquitectura técnica; es, sobre todo, un enfoque organizativo que redefine la propiedad del dato, los flujos de trabajo y la responsabilidad. Su objetivo es permitir que las empresas escalen sus capacidades analíticas sin caer en cuellos de botella operativos.
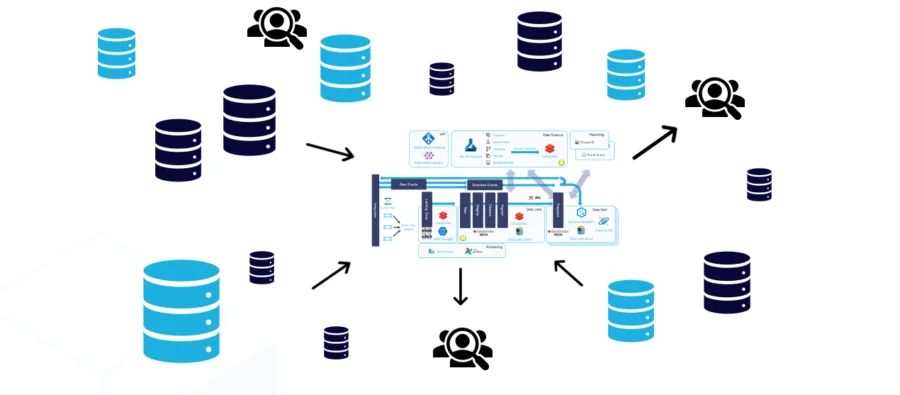
¿Qué es Data Mesh? El enfoque sociotécnico que está redefiniendo la gestión moderna de datos
Data Mesh no debe entenderse únicamente como una nueva arquitectura de datos: es, sobre todo, un cambio profundo en la forma en que las organizaciones se relacionan con sus datos. Supone un giro desde modelos centralizados —como data warehouses o data lakes tradicionales— hacia una estructura distribuida, autónoma y altamente escalable.
En los enfoques centralizados, un único equipo técnico suele encargarse de construir, limpiar, transformar y servir los datos a toda la organización. Este modelo funciona en etapas tempranas, pero cuando la empresa crece y se multiplica el volumen de información, aparecen problemas evidentes:
- Cuellos de botella operativos
- Retrasos en la entrega de datasets
- Falta de claridad sobre la responsabilidad real
- Sobrecarga del equipo central
- Sistemas frágiles y difíciles de escalar
Data Mesh nace para resolver precisamente esos desafíos. Su punto de partida es simple pero revolucionario: los datos deben gestionarse allí donde se generan y se entienden mejor, no en un único equipo central que intenta abarcarlo todo.
El enfoque se articula en torno a cuatro principios fundamentales. Cada uno representa un cambio cultural, organizativo y técnico que permite a las empresas escalar la analítica al ritmo de su negocio.
Los cuatro pilares de Data Mesh
1. Propiedad de datos por dominios
En Data Mesh, cada dominio del negocio —como ventas, logística, marketing, finanzas u operaciones— se convierte en el encargado de gestionar los datos que produce. Esto implica que estos equipos definen:
- Los registros que forman parte del dominio
- Las reglas de calidad y validación
- Los modelos semánticos que describen la información
- Las políticas de acceso y seguridad
- Los mecanismos de actualización y mantenimiento
De este modo, el conocimiento deja de concentrarse en un equipo de datos central y se traslada a quienes mejor entienden el contexto: los equipos operativos.
Este cambio evita malentendidos, elimina dependencias innecesarias y permite que cada equipo evolucione sus productos de datos a la velocidad del negocio.

2. Datos como producto
Uno de los pilares más transformadores de Data Mesh es la idea de considerar los datos como productos con usuarios internos, no como simples salidas técnicas. Esto implica adoptar una mentalidad de producto:
- Calidad verificable con métricas transparentes
- Documentación accesible, clara y actualizada
- Disponibilidad estable, con acuerdos de nivel de servicio (SLA)
- Gobernanza explícita, sin ambigüedades
- Acceso autoservicio, sin fricciones ni esperas
Cada dominio debe crear datasets que puedan ser descubiertos, consumidos y reutilizados por otros equipos sin necesidad de un intermediario técnico. El resultado es un catálogo vivo de productos de datos confiables y bien mantenidos, que fomenta la interoperabilidad y acelera la analítica.
3. Plataforma de datos autoservicio
Para habilitar la autonomía de los dominios sin generar duplicaciones o caos técnico, Data Mesh se apoya en una plataforma central de autoservicio. Esta plataforma ofrece capacidades transversales que todos los dominios comparten:
- Gestión de metadatos y catalogación
- Procesamiento y orquestación
- Seguridad, auditoría y accesos
- Observabilidad y monitorización
- Infraestructura escalable y automatizada
Su misión no es controlar los datos, sino proporcionar un entorno común que:
- Simplifique el trabajo de los equipos
- Reduzca la carga técnica
- Garantice estándares mínimos de calidad
- Evite la reinvención de soluciones
La plataforma actúa como el “sistema operativo” del Data Mesh.
4. Gobernanza federada
El modelo de Data Mesh combina autonomía y coherencia. Aunque cada dominio gestiona sus propios datos, todos deben alinearse con estándares globales. La gobernanza federada establece:
- Lenguajes y definiciones semánticas compartidas
- Políticas de privacidad y seguridad uniformes
- Criterios de calidad obligatorios
- Protocolos para asegurar la interoperabilidad
Este enfoque evita la fragmentación y mantiene el ecosistema de datos cohesionado, sin recurrir al control rígido que caracteriza a los modelos puramente centralizados.

El objetivo final: una analítica que escala con el negocio
En última instancia, Data Mesh busca resolver un problema que la mayoría de grandes organizaciones comparten: cómo seguir creciendo sin hundirse bajo el peso de sus propios datos.
Al descentralizar la responsabilidad, distribuir la carga y estructurar los datos como productos, la empresa puede:
- Innovar más rápido
- Mantener estándares comunes
- Reducir dependencias críticas
- Mejorar la calidad de la información
- Escalar la capacidad analítica de forma sostenible
Ventajas de adoptar Data Mesh
1. Escalabilidad organizativa real
Los modelos centralizados dependen de un único equipo técnico. Cuando el negocio crece, ese equipo se colapsa.
Data Mesh rompe ese cuello de botella:
- Cada dominio puede crear nuevos datasets sin esperar a un backlog central
- Los pipelines evolucionan de manera independiente
- La integración de nuevas fuentes no paraliza a toda la organización
La analítica escala al ritmo del negocio, no al ritmo del equipo central.
2. Mayor calidad gracias al conocimiento experto
Los datos gestionados desde el origen capturan mejor la realidad operativa:
- Se aplican reglas de negocio más precisas
- Disminuyen los errores de interpretación
- Se corrigen problemas de calidad más rápido
- La información es más confiable y consistente
El resultado es una base de datos más sana y alineada con la actividad real.

3. Cultura de autonomía, colaboración y responsabilidad
Data Mesh promueve un nuevo modo de trabajar:
- Los equipos comparten sus datos como productos reutilizables
- Se reduce la duplicación de esfuerzos
- Cada dominio asume responsabilidad sobre la calidad
- Se construye una cultura orientada a la interoperabilidad
A largo plazo, las empresas desarrollan una madurez analítica superior.
4. Menor dependencia del equipo central de datos
El equipo central deja de ser un cuello de botella y se transforma en un habilitador estratégico:
- Define estándares
- Mantiene la plataforma
- Provee herramientas
- Asegura la gobernanza
Los recursos técnicos especializados se utilizan mejor y el negocio gana velocidad.
Desafíos del Data Mesh
Aunque sus beneficios son significativos, Data Mesh también implica retos notables.

1. Alto coste organizativo y cultural
Implementarlo requiere:
- Nuevos roles como “data product owner”
- Formación en calidad, gobierno y producto
- Nuevas dinámicas de colaboración
- Procesos transversales claros y maduros
Es una transformación cultural antes que tecnológica.
2. Riesgo de inconsistencia entre dominios
Sin gobernanza federada, pueden surgir problemas como:
- Datasets incompatibles
- Modelos duplicados
- Definiciones incoherentes
La coordinación entre dominios es clave para evitar la fragmentación.
3. Dependencia de una plataforma fuerte
Si no existe una plataforma robusta con:
- catalogación,
- seguridad,
- monitorización,
- orquestación,
- automatización,
la descentralización puede derivar en caos. La plataforma es el pilar técnico que permite la autonomía.
4. Cambio de mentalidad del negocio
Muchos equipos no están habituados a pensar en sus datos como “productos”. Asumir responsabilidad continua sobre la calidad y disponibilidad puede requerir:
- Acompañamiento
- Formación
- Tiempo de adopción
Es un cambio profundo en la cultura organizativa.
Cuándo Data Mesh aporta verdadero valor
Data Mesh no es un modelo universal. Funciona especialmente bien en organizaciones con alta complejidad o necesidades de escalabilidad avanzada.
1. Corporaciones con múltiples dominios
En empresas grandes y diversificadas, Data Mesh facilita:
- Conectar silos
- Unir diferentes sistemas
- Mantener autonomía local con reglas globales
Es común en sectores como banca, telecomunicaciones, retail o industria pesada.

2. Organizaciones en rápido crecimiento
Cuando el volumen de datos aumenta más rápido que la capacidad del equipo central, Data Mesh evita la saturación y permite escalar de forma sostenible.
3. Empresas digitales o tecnológicas
Las organizaciones nativas digitales suelen trabajar en equipos autónomos, lo que encaja de forma natural con el modelo distribuido.
4. Entornos dinámicos con cambios constantes en los datos
Sectores como logística, ecommerce, movilidad o fintech se benefician especialmente al poder adaptar productos de datos en tiempo real.
5. Empresas con ambiciones de analítica avanzada
Data Mesh crea el entorno ideal para:
- Machine learning distribuido
- IA generativa aplicada al negocio
- Analítica en tiempo real
- Modelos predictivos complejos
- Sistemas de recomendación
La calidad y la gobernanza del dato se vuelven pilares esenciales para sostener estas capacidades.

¿Es Data Mesh la solución para todas las empresas?
No. Aunque es potente y transformador, Data Mesh no es adecuado para organizaciones pequeñas o con necesidades analíticas limitadas. En esos casos, un modelo centralizado es más simple, eficiente y fácil de mantener.
Data Mesh brilla cuando:
- La organización es grande.
- Los datos están muy distribuidos.
- Existen equipos autónomos.
- Se busca escalar sin sobrecargar un equipo central.
Por ello, más que una moda, debe entenderse como un cambio profundo que requiere madurez, visión y compromiso.
Muy interesante el DataMesh